TinyAgent: Enabling Function Calling and Edge Agent Workflows with Small Language Models
Sources: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent
TL;DR
- TinyAgent demonstrates that properly fine-tuned small language models can perform reliable function calling and orchestrate tool usage at the edge, reducing reliance on cloud inference.
- The approach combines curated synthetic data, an LLMCompiler planner, and a Tool RAG workflow to enable private, low-latency agentics on devices like a MacBook.
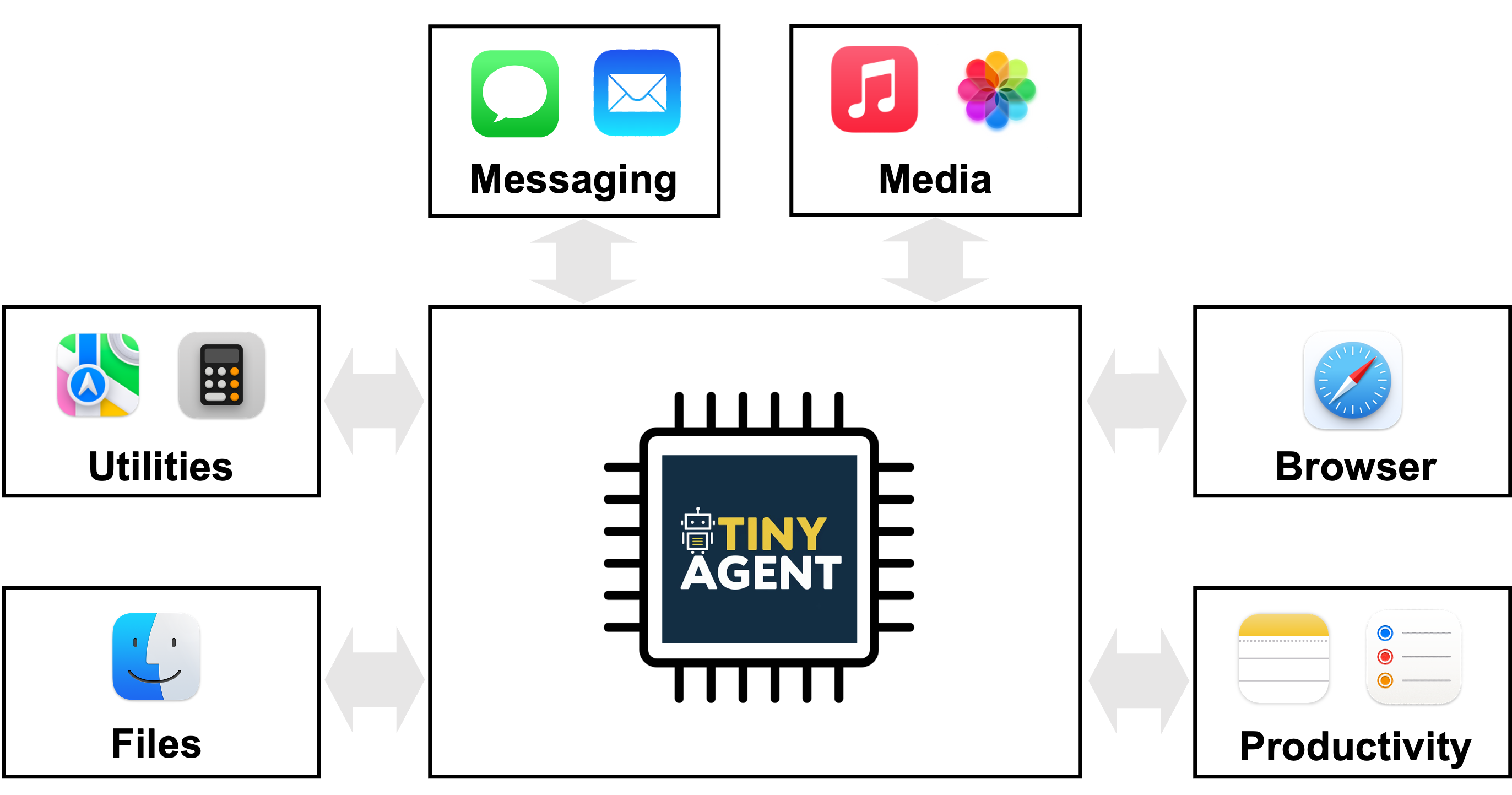
- The project uses a driving application on macOS with 16 pre-defined functions that interface with system apps, and demonstrates a TinyAgent-1B model running locally with Whisper-v3 on a MacBook M3 Pro.
- Data generation relied on a GPT-4-Turbo-like setup to produce 80K training examples plus 1K validation and 1K test examples, at a total cost of roughly $500; the framework is open source.
- The work suggests that small models, when fine-tuned on high-quality task-specific data, can exceed larger models’ function calling capabilities in constrained settings. Source GitHub
Context and background
Recent advances in large language models (LLMs) have shown that agents can execute commands by translating user queries into a sequence of tool calls, enabling systems that orchestrate APIs and scripts to fulfill tasks. This family of “agentic” capabilities typically relies on cloud-based inference because of model size and compute demands. However, cloud-based operation raises privacy concerns when data such as video, audio, or documents are uploaded, and connectivity or latency issues can hinder real-world deployments—such as robots operating with unstable networks. The TinyAgent work frames a path toward secure, private, low-latency agentic workflows by deploying small language models locally on edge devices. The authors emphasize that many general knowledge memorized by large models is not needed for specialized edge tasks, suggesting that targeted data and function-calling skills can replace broad world knowledge for many practical tasks. This context motivates a shift toward compact, edge-friendly agents that can understand user intent and orchestrate pre-defined functions or APIs without exporting data to the cloud. Source The project centers on making small open-source models capable of accurate function calling, a core component of agentic systems. Prior work showed that off-the-shelf small models struggle to output correct function-call plans, with issues in function selection, input arguments, dependencies, and syntax. TinyAgent tackles this gap by curating a high-quality, task-specific dataset designed to teach how to emit correct function-calling plans with proper dependencies. The driving application is a local macOS agent that can interact with 16 predefined functions tied to macOS applications, illustrating how an edge-based assistant can understand natural language queries and translate them into concrete function calls rather than generic Q&A responses. Source What makes TinyAgent notable is the combined methodology: data curation, fine-tuning, and an architectural layer that handles planning and execution. The approach uses an LLMCompiler planner to generate a sequence of interdependent tasks from a user query, then dispatches those tasks through a curated function-call plan. After the plan is generated, its dependencies are resolved by executing the corresponding functions in the correct order, with placeholder variables replaced by actual results before downstream tasks execute. This separation of planning and execution helps small models deliver accurate tool orchestration without memorizing broad world knowledge. Source
What’s new
TinyAgent advances the state of the art for edge-enabled agents in several ways. First, it demonstrates that fine-tuning small language models on a high-quality, synthetic dataset tailored for function calling can push performance beyond what some larger, open models can achieve in the same function-calling task. The dataset is generated by instructing a capable LLM to produce realistic user queries that map to a predefined set of macOS functions, along with the required input arguments and the correct dependency graph for the plan. Sanity checks ensure the function graph forms a feasible DAG and that function names and input types align with the available APIs. Second, the project introduces a Tool RAG method to further improve efficiency and accuracy in function calling and orchestration. Third, TinyAgent demonstrates a full edge deployment pipeline using TinyAgent-1B and Whisper-v3 running locally on a MacBook M3 Pro, underscoring the practical feasibility of private, latency-sensitive agentics on consumer hardware. The framework is openly available at the project’s GitHub repository. Source GitHub A practical demonstration centers on a local Mac environment where 16 predefined functions can interact with various macOS applications via predefined Apple scripts. The work emphasizes that the model’s job is to determine which functions to call, the corresponding inputs, and the right sequencing—without writing the function definitions themselves, since the functions are pre-defined by the system. This distinction is central to enabling edge deployment: the model focuses on orchestration rather than memorization of generic knowledge. The LLMCompiler framework is depicted as a planner that understands user queries and produces a task sequence with interdependencies that can be executed by the system. Source
Why it matters (impact for developers/enterprises)
For developers and enterprises, TinyAgent offers a blueprint for building private, edge-first AI assistants that operate with low latency and without sending user data to third-party cloud services. The approach addresses privacy concerns by keeping processing local and reducing reliance on network connectivity, which is especially important for embedded devices, autonomous agents, or enterprise-grade edge deployments. By focusing on function calling rather than broad world knowledge, TinyAgent reduces the computational footprint required for agentic reasoning, potentially enabling small models to perform complex orchestration tasks that previously required larger systems. This aligns with a broader push toward on-device AI that preserves user privacy while sustaining responsive user experiences. Source The work also demonstrates a practical data-generation workflow for training small models on narrow, high-value capabilities. Rather than relying on expensive, hand-crafted data, the authors synthesized 80,000 training examples plus 1,000 validation and 1,000 test examples using a capable LLM to generate realistic prompts and corresponding function-calling plans. Sanity checks ensured the generated plans formed valid DAGs with correct function names and argument types. The reported dataset size was achieved at roughly $500, illustrating the cost-effectiveness of scale for edge-focused tasks. This data-centric approach can inform other teams seeking to empower compact models with specialized planning and orchestration abilities. Source
Technical details or Implementation
The architecture centers on enabling small open-source models to perform accurate function calling, a core capability for agent-like behavior. A key component is the LLMCompiler planner, which translates user queries into a function-calling plan that specifies the functions to call, the inputs, and the dependencies between calls. The planner outputs a plan that is then parsed and executed in dependency order. A critical observation is that while large models can generate such plans, smaller models initially fail due to issues like incorrect function sets, hallucinated names, wrong dependencies, and syntax errors. TinyAgent addresses this by curating a high-quality dataset and applying targeted fine-tuning, enabling small models to produce valid function-calling plans and surpass reference baselines in some cases. Source The data-generation strategy is central to the approach. Rather than handcrafted data, the researchers used an LLM (akin to GPT-4-Turbo) to generate synthetic, task-specific prompts, each paired with a correct function-calling plan and input arguments. The generated data then underwent sanity checks to ensure the graph structure was feasible and that function names and input-argument types matched the predefined Mac functions. This process yielded an 80K training set, with 1K validation and 1K test samples. The total cost for generating this data was about $500, underscoring a scalable approach to data-centric model improvement for edge tasks. Source A notable innovation is the introduction of Tool RAG, a method to improve efficiency and accuracy in how tools are selected and invoked by the model. The combination of curated data, targeted fine-tuning, and Tool RAG supports the creation of edge-ready agents that can operate with real-time responsiveness. TinyAgent-1B, paired with Whisper-v3 for local audio processing, was demonstrated on a MacBook Pro ecosystem, illustrating a practical edge deployment scenario. The project is openly available for inspection and adaptation at the code repository. Source GitHub From a software architecture perspective, the pipeline is: user query → LLMCompiler planner → function-calling plan with dependencies → execution of functions in dependency order → replacement of placeholder variables with actual results → downstream tasks completion. The planner is designed so the model focuses on deciding which functions to call, the inputs, and the ordering, rather than generating new function definitions. This design mirrors real-world usage where applications expose predefined APIs or scripts that the agent can orchestrate. The project also illustrates a DAG (Directed Acyclic Graph) evaluation metric: the isomorphism between the generated plan DAG and the ground-truth DAG indicates success when the overall task structure matches even if the exact ordering varies. Source In short, TinyAgent provides a proof of concept and a practical pathway for deploying compact language models at the edge to perform reliable function calling and tool orchestration, supported by a rigorous data-generation and validation workflow and a ready-to-use open-source implementation. The evidence includes a working demonstration of TinyAgent-1B plus Whisper-v3 on a MacBook Pro platform and a publicly available codebase for replication and extension. Source GitHub
Key takeaways
- Small language models can be trained to perform function calling accurately for edge deployments when guided by high-quality, task-specific data.
- A dedicated planner (LLMCompiler) can translate user intents into a structured plan of function calls with explicit dependencies.
- Tool RAG and curated data enable efficient, private orchestration of macOS applications via predefined scripts and APIs.
- Edge deployment using TinyAgent-1B and Whisper-v3 on a MacBook Pro demonstrates real-world viability for private, low-latency AI agents.
- The approach emphasizes data-centric model improvement and reproducibility through open source tooling and community access. Source GitHub
FAQ
-
What problem does TinyAgent address?
It shows how small language models can be fine-tuned to perform reliable function calling and be deployed at the edge for private, low-latency agent workflows.
-
How is the training data generated?
A capable LLM (GPT-4-Turbo-like) generates synthetic, task-specific user queries, corresponding function calls, and input arguments; sanity checks verify DAG feasibility and input types, yielding 80K training, 1K validation, and 1K test examples for about $500 total cost. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/)
-
What’s the role of LLMCompiler and Tool RAG?
LLMCompiler produces a function-calling plan with function choices, inputs, and dependencies; Tool RAG improves efficiency in tool selection and invocation during execution. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/)
-
How is the edge deployment demonstrated?
The TinyAgent-1B model, together with Whisper-v3, runs locally on a MacBook Pro environment, interfacing with 16 predefined macOS functions. [Source](http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/)
-
Where can I access the code?
The project is open source at the TinyAgent GitHub repository. [GitHub](https://github.com/SqueezeAILab/TinyAgent)
References
- TinyAgent blog post: http://bair.berkeley.edu/blog/2024/05/29/tiny-agent/
- TinyAgent GitHub repository: https://github.com/SqueezeAILab/TinyAgent
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

NVIDIA HGX B200 Reduces Embodied Carbon Emissions Intensity
NVIDIA HGX B200 lowers embodied carbon intensity by 24% vs. HGX H100, while delivering higher AI performance and energy efficiency. This article reviews the PCF-backed improvements, new hardware features, and implications for developers and enterprises.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.