Modeling Extremely Large Images End-to-End with xT: Nested Tokenization and Long-Context Vision
TL;DR
- xT is a framework that models gigapixel-scale images end-to-end on contemporary GPUs using nested tokenization, region encoders, and long-context vision encoders.
- It breaks large images into regions, processes each region with a regional encoder, and stitches the results with a long-sequence context encoder.
- xT can handle images as large as 29,000 × 25,000 pixels on 40GB A100 GPUs; comparable baselines fail beyond ~2,800 × 2,800.
- The approach yields higher accuracy on downstream tasks with fewer parameters and lower memory per region, across datasets like iNaturalist 2018, xView3-SAR, and MS-COCO.
- The authors discuss various backbone options for region encoders and long-context models (e.g., Swin, HierA, ConvNeXt; Transformer-XL variants such as Hyper and Mamba), and point to a project page with released code and weights. BAIR BAIR Blog.
Context and background
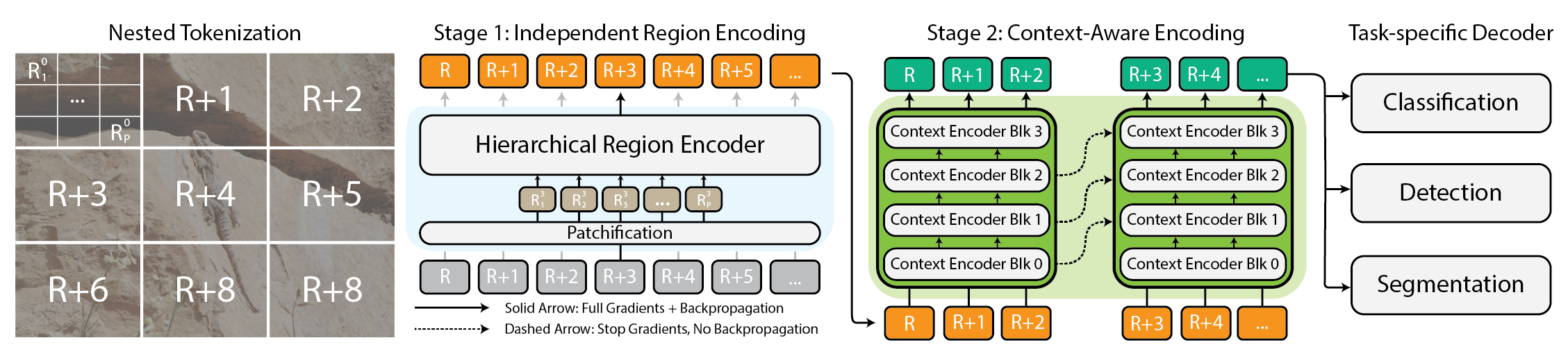
Large, high-resolution images pose a fundamental challenge for computer vision: memory usage tends to grow roughly quadratically with image size, making end-to-end processing impractical on standard hardware. Traditional approaches, such as down-sampling or cropping, trade away crucial information and context, impairing both global understanding and local details. The xT work from BAIR argues that it should be possible to model these images end-to-end while preserving both forest and trees. The authors emphasize that every pixel can carry meaningful information, whether viewed in a broad landscape or at a fine-grained patch. The motivation is to avoid compromising the full narrative of an image, from wide-angle context to small but critical details. BAIR BAIR Blog. In this light, xT introduces a hierarchical approach to tokenization that decomposes a gigantic image into manageable parts, then analyzes each part before reconciling the pieces into a global representation. This nested tokenization creates a multi-scale view that retains local fidelity while enabling cross-region context. The framework uses two kinds of encoders: a region encoder to process local regions, and a context encoder to combine region-level insights across the image.
What’s new
The core novelty of xT lies in its nested tokenization and the dual-encoder paradigm. First, the image is divided into regions and further subdivided in a hierarchical fashion into sub-regions as needed by the vision backbone. Each region is tokenized and processed by a region encoder, which can be any modern vision backbone such as Swin or HierA, or even ConvNeXt. Second, a long-sequence context encoder takes the detailed representations from all regions and stitches them together to produce a global understanding of the image. The context encoder is designed for long sequences and is explored with Transformer-XL variants (including a BAIR variant named Hyper) and Mamba; Longformer and other long-sequence models are mentioned as possible alternatives. This arrangement enables end-to-end processing of gigapixel-scale imagery on contemporary GPUs. In experiments highlighted by BAIR, the method scales to 29,000 × 25,000 pixel images on 40GB A100 GPUs, while comparable baselines encounter memory bottlenecks well below that scale (around 2,800 × 2,800). The paper also reports that, across tasks, xT achieves higher accuracy with fewer parameters and lower memory per region than strong baselines. The authors note a broad applicability across domains, including climate monitoring and healthcare, where seeing both the big picture and the details matters. For a complete treatment, see the arXiv paper referenced by the authors, and visit the project page for code and weights. BAIR BAIR Blog. In terms of implementation, region encoders can be standard backbones, while the context encoder handles cross-region relationships. The authors emphasize that processing regions in isolation is not enough; the context encoder is what brings the global coherence to the representation. This separation of concerns—local feature extraction and global context integration—allows xT to balance detail with scale.
Why it matters (impact for developers/enterprises)
The ability to process gigapixel-scale images end-to-end changes several practical dimensions:
- It preserves more information across scales, improving downstream task performance without simply scaling down inputs.
- It reduces memory pressure per region and overall memory usage, enabling larger inputs to be processed on standard hardware like 40GB A100 GPUs.
- It supports diverse downstream tasks, demonstrated on datasets spanning fine-grained classification, context-dependent segmentation, and object detection.
- The approach aligns with scientific and clinical workflows where exploring both global trends and local patches can be pivotal for insights, from climate assessments to early-disease detection. The BAIR team frames xT as a stepping stone toward models that can juggle large-scale structure with localized detail without compromise. The work also hints at a broader ecosystem, with ongoing follow-ons to expand the frontier further and to release code and weights for researchers and practitioners. BAIR BAIR Blog.
Technical details or Implementation
At a high level, xT composes three ideas to tackle gigapixel-scale images:
- Nested tokenization: a hierarchical breakdown of the image into regions and sub-regions, which are then patchified for analysis by region encoders. This hierarchical tokenization enables multi-scale feature extraction on a local level.
- Region encoders: standalone local experts that convert independent regions into rich representations. These encoders can be state-of-the-art backbones such as Swin, HierA, or ConvNeXt. Importantly, processing is performed region-by-region to keep memory usage manageable. BAIR BAIR Blog.
- Context encoders: long-sequence models that aggregate regional representations to capture global context. The authors explore Transformer-XL and their Hyper variant, as well as Mamba; they also acknowledge Longformer as a potential alternative in this space. This component ensures that distant regions are interconnected in the final representation. The interplay between the region encoder and the context encoder is central: regions are first analyzed locally, and the resulting features are then linked through a long-context model to form a coherent global interpretation of the image. This design enables end-to-end training and inference on large images while keeping memory within practical limits. BAIR BAIR Blog. For reference, the authors evaluate xT on a suite of challenging tasks, including iNaturalist 2018 for fine-grained species classification, xView3-SAR for context-dependent segmentation, and MS-COCO for detection. Across these tasks, xT demonstrates higher accuracy with fewer parameters and markedly reduced memory per region compared to baselines. The authors emphasize that their results are enabled by the combination of nested tokenization, region encoders, and context encoders—proof that large-scale vision can be tackled end-to-end on modern hardware. BAIR BAIR Blog.
Memory and scale: a compact comparison
| Image size (pixels) | Hardware |
| Notes |
|---|
| --- |
| --- |
| 29,000 × 25,000 |
| xT can model this scale end-to-end. BAIR Blog. |
| 2,800 × 2,800 |
| The experimental narrative underscores a practical advantage: the same architectural primitives—region encoders and context encoders—support a wide range of backbones and long-context models, enabling researchers and practitioners to tailor the system to their data and compute constraints. The authors point readers to the arXiv paper for a complete treatment and to the project page for code and weights. BAIR BAIR Blog. |
Key takeaways
- xT enables end-to-end processing of gigapixel images by combining nested tokenization with region-level and global context encoders.
- The framework achieves high fidelity on very large images (up to 29,000 × 25,000) on 40GB A100 hardware, a scale that challenges many existing baselines.
- Region encoders can be Swin, HierA, or ConvNeXt, while context encoders explore Transformer-XL variants like Hyper and Mamba, with Longformer as a potential alternative.
- Downstream gains include better accuracy with fewer parameters and reduced per-region memory usage across tasks like iNaturalist 2018, xView3-SAR, and MS-COCO.
- A project page provides access to released code and weights, with the arXiv paper offering a complete treatment. BAIR BAIR Blog.
FAQ
-
What problem does xT solve?
It models gigapixel-scale images end-to-end on GPUs using a hierarchical tokenization approach that preserves both global context and local details. It scales to 29,000 × 25,000 pixels on 40GB A100s, outperforming baselines that struggle with memory at much smaller sizes. [BAIR Blog](http://bair.berkeley.edu/blog/2024/03/21/xt/).
-
How does nested tokenization work?
The image is broken into regions, which may be subdivided hierarchically and patchified for region encoders. The region-level representations are then fed into a long-context encoder to integrate information across the entire image. [BAIR Blog](http://bair.berkeley.edu/blog/2024/03/21/xt/).
-
What encoders does xT employ?
Region encoders can be Swin, HierA, or ConvNeXt, while the context encoder is a long-sequence model such as Transformer-XL variants (Hyper, Mamba) or Longformer as an option. [BAIR Blog](http://bair.berkeley.edu/blog/2024/03/21/xt/).
-
On which tasks was xT evaluated?
iNaturalist 2018 for fine-grained species classification, xView3-SAR for context-dependent segmentation, and MS-COCO for detection. The results indicate higher accuracy with fewer parameters and lower memory per region. [BAIR Blog](http://bair.berkeley.edu/blog/2024/03/21/xt/).
-
Where can I access the code and weights?
The project page linked from the BAIR blog provides access to released code and weights. The arXiv paper offers the complete treatment. [BAIR Blog](http://bair.berkeley.edu/blog/2024/03/21/xt/).
References
- BAIR Berkeley AI Research blog post: Modeling Extremely Large Images End-to-End with xT — Nested Tokenization and Long-Context Vision. http://bair.berkeley.edu/blog/2024/03/21/xt/
More news

First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

NVIDIA HGX B200 Reduces Embodied Carbon Emissions Intensity
NVIDIA HGX B200 lowers embodied carbon intensity by 24% vs. HGX H100, while delivering higher AI performance and energy efficiency. This article reviews the PCF-backed improvements, new hardware features, and implications for developers and enterprises.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Predict Extreme Weather in Minutes Without a Supercomputer: Huge Ensembles (HENS)
NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway Joins Hugging Face Inference Providers for Serverless, Low-Latency Inference
Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Google expands Gemini in Chrome with cross-platform rollout and no membership fee
Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.