Do Text Embeddings Fully Encode Input? Vec2Text Shows Near-Perfect Inversion
TL;DR
- vec2text demonstrates near-perfect inversion of 32-token input embeddings produced by a text embedding model, raising questions about embedding security.
- An initial approach trained a transformer to map embeddings back to text, achieving a BLEU score around 30/100 with an exact-match rate near zero.
- A learned optimization approach improves results: a single correction pass raises BLEU to 50; with 50 iterative steps, about 92% of 32-token sequences are recovered exactly, and BLEU reaches 97.
- The work highlights privacy risks for retrieval augmented generation (RAG) systems and vector databases that store embedding vectors, since fixed-size embeddings can still preserve substantial information about the input.
Context and background
Retrieval Augmented Generation (RAG) has become a common pattern for building AI systems that answer questions from document collections. In RAG, documents are represented as embeddings, vectorized forms meant to capture semantic similarity, and a database of these embeddings is used to retrieve relevant material before generation. Because embeddings are high-dimensional numeric vectors, there is no straightforward way to retrieve the original text from the vector itself; embeddings are often viewed as a lossy, non-invertible representation. The broader idea that information can be compressed into neural representations without perfect recoverability is well known in theory. The data processing inequality, a principle from signal processing, suggests that functions cannot add information to the input and may discard information through nonlinearities like ReLU, which is common in embedding models. Early work in other domains has shown that deep representations can be inverted to recover the input to some degree, such as reconstructing images from feature outputs of neural networks. In the text domain, the question is whether a similar inversion is possible and to what extent. The researchers frame a toy problem to study inversion: 32 input tokens mapped to 768-dimensional embedding vectors, yielding 24,576 bits (about 3 kilobytes) at 32-bit precision. They probe whether a faithful reconstruction of the original text is feasible from these embeddings and how to measure reconstruction quality. A key observation is that while exact input recovery is hard in a single pass, two kinds of similarity metrics matter: text-level similarity (BLEU) and embedding-level similarity (cosine similarity). They also note that the embedding process may map multiple inputs to similar embeddings, a potential collision that would limit recoverability. In their experiments, they report that their embedder did not exhibit harmful collision behavior in practice, which allowed them to pursue inversion strategies with meaningful fidelity. The study references prior results in image inversion, where high-level features can be inverted to blurry—but meaningful—reconstructions, to motivate exploring text inversion in a similar fashion. The specific paper underpinning these results is Text Embeddings Reveal As Much as Text (EMNLP 2023), which tackles the core question of whether input text can be recovered from embeddings. The Gradient article. The analysis in this work emphasizes that embeddings have a fixed size and a fixed information budget. That raises important questions about how much text can be stored and recovered from such vectors, and what this implies for the privacy of documents processed with embedding-based systems.
What’s new
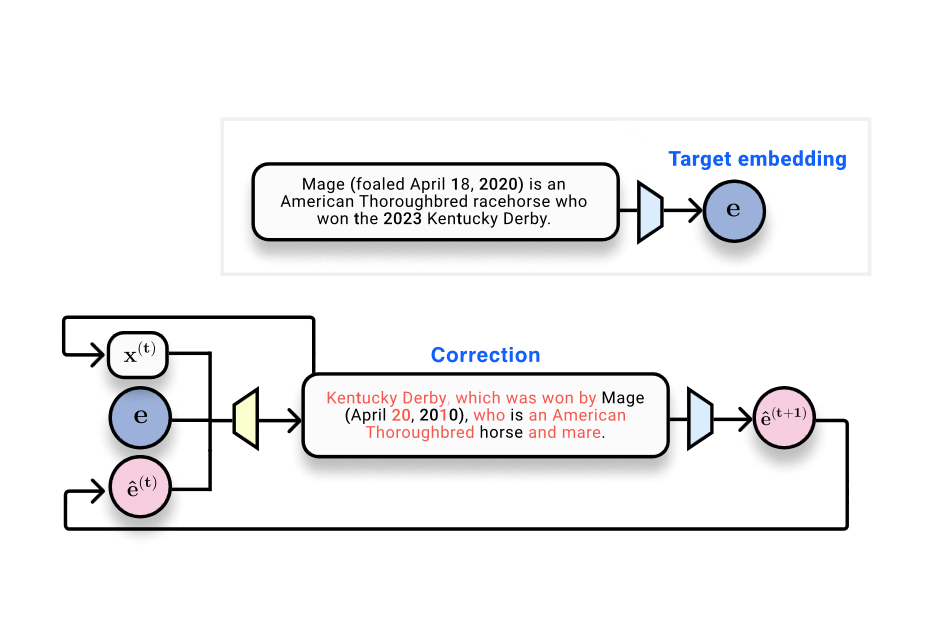
- The authors introduce vec2text, a method that treats embedding inversion as a learned optimization problem in embedding space. It combines a ground-truth embedding with a current hypothesis and the hypothesis’s location in embedding space to predict the true text sequence.
- A straightforward baseline approach—train a transformer to map an embedding back to text—achieves a BLEU score of about 30/100 and an almost-zero exact-match rate, highlighting the difficulty of reversing a neural embedding in one shot. The Gradient article.
- The key innovation is a corrective model, applied iteratively, that can refine guesses in embedding space. A single forward pass of correction raises BLEU from 30 to 50, and the system can be run recursively to improve results further.
- With 50 iterative steps and a few tricks, the method recovers about 92% of 32-token sequences exactly and achieves a BLEU score of 97, indicating near-perfect reconstruction for the tested length.
- The results demonstrate that, for short inputs, text embeddings can be inverted with surprisingly high fidelity, prompting questions about their use as secure or lossy representations in practice.
Why it matters (impact for developers/enterprises)
The study directly engages a practical concern for organizations relying on embeddings and vector databases: are embeddings truly a secure, lossy representation of text, or can sensitive inputs be reconstructed from the stored vectors? The model uses a fixed-size embedding and shows that substantial information about the input can be recovered under certain conditions. This has implications for systems that store embeddings rather than raw text, especially when those vectors are accessible to third parties or could be leaked in a data breach. For developers and enterprises building RAG pipelines, the work underscores the need to consider privacy protections and data governance around embeddings. If an attacker gains access to embedding vectors and the embedding model’s details, there is a potential pathway to reconstruct inputs, particularly for shorter text sequences. The feasibility demonstrated here does not imply that all inputs can always be perfectly recovered, but it does show that compression via embeddings may not be as lossy as widely assumed for all sequences.
Technical details or Implementation
- Experimental setup: the base scenario encodes 32 tokens into a 768-dimensional embedding per token, totaling a fixed-length embedding vector. In this toy setting, 32 tokens map to 24,576 bits (about 3 KB) at 32-bit precision.
- Baseline inversion: the researchers trained a transformer to take the embedding as input and generate the corresponding text. This approach produced a BLEU score of roughly 30/100, indicating topic familiarity but poor word order and many incorrect tokens. Exact-match recovery was near zero.
- Embedding-space similarity check: when they re-embedded the model’s generated text (the hypothesis) and compared it to the ground-truth embedding, they observed a high cosine similarity of about 0.97. This suggested that the generated text resided in the same embedding region as the ground truth, even if not identical.
- Learned optimization (vec2text): inspired by the embedding-space similarity, the authors introduced a corrective model that, given a ground-truth embedding, a hypothesis text, and the hypothesis’s current position in embedding space, predicts text closer to the ground truth than the hypothesis.
- Single-pass improvement: applying the correction once increased BLEU from 30 to 50, demonstrating a meaningful improvement and motivating iterative refinement.
- Recursive refinement: vec2text can be queried recursively by taking the corrected text, re-embedding it, and feeding it back into the model for further improvements. With 50 steps and additional tricks, they achieved 92% exact recovery on 32-token sequences and BLEU scores of 97, indicating near-perfect reconstruction in this setting.
- Conceptual takeaway: the process frames inversion as a discrete optimization in embedding space, rather than a single-shot generation task. This is the essence of vec2text—the learned optimization loop that progressively aligns a hypothesis with the ground-truth embedding.
A compact data table of key figures
| Aspect | Value
| --- |
|---|
| Token count in test input |
| Embedding dimension |
| Embedding size total (32 tokens) |
| Baseline BLEU (embedding->text) |
| Baseline exact match |
| Single correction BLEU (vec2text pass) |
| 50-step iterative restoration |
Key takeaways
- Text embeddings can be inverted with high fidelity for short sequences, challenging the assumption that embeddings are secure and lossy representations.
- A single correction step in embedding space can substantially improve reconstruction quality, and iterative refinement can approach near-perfect recovery for 32-token inputs.
- The ability to recover input from embeddings has privacy and security implications for RAG systems and vector databases, underscoring the need for careful data governance.
- The results underline a fundamental tradeoff: while embeddings enable efficient similarity search, they may also preserve substantial information about the original input for certain texts and lengths.
FAQ
-
Can input text be recovered from embeddings?
Yes. vec2text demonstrates near-perfect inversion for 32-token sequences, with a single correction pass improving BLEU from 30 to 50 and iterative steps achieving 92% exact recovery and BLEU of 97. [The Gradient article](https://thegradient.pub/text-embedding-inversion/).
-
What are the limitations of these results? How far do they extend?
The reported results focus on 32-token inputs and a fixed embedding setup. While they show high fidelity in this setting, the authors discuss the fixed-size embedding and the question of information capacity, noting that longer inputs may present different challenges.
-
What are the implications for data privacy in embedding-based systems?
If embedding vectors are exposed or leaked, there is a potential pathway to reconstruct input text, particularly for shorter sequences, which raises privacy concerns for RAG deployments and vector databases.
-
What is vec2text in simple terms?
Vec2text is a corrective, optimization-style method that operates in embedding space to turn a guess into text that more closely matches the original input, and it can be applied iteratively for improved accuracy.
References
- The Gradient. Do Text Embeddings Fully Encode Input? Vec2Text Shows Near-Perfect Inversion. https://thegradient.pub/text-embedding-inversion/
More news

NVIDIA HGX B200 Reduces Embodied Carbon Emissions Intensity
NVIDIA HGX B200 lowers embodied carbon intensity by 24% vs. HGX H100, while delivering higher AI performance and energy efficiency. This article reviews the PCF-backed improvements, new hardware features, and implications for developers and enterprises.

Shadow Leak shows how ChatGPT agents can exfiltrate Gmail data via prompt injection
Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

Move AI agents from proof of concept to production with Amazon Bedrock AgentCore
A detailed look at how Amazon Bedrock AgentCore helps transition agent-based AI applications from experimental proof of concept to enterprise-grade production systems, preserving security, memory, observability, and scalable tool management.

Teen safety, freedom, and privacy
Explore OpenAI’s approach to balancing teen safety, freedom, and privacy in AI use.

Streamline ISO-rating content changes with Verisk Rating Insights and Amazon Bedrock
Verisk Rating Insights, powered by Amazon Bedrock, LLMs, and RAG, enables a conversational interface to access ISO ERC changes, reducing manual downloads and enabling faster, accurate insights.

OpenAI introduces GPT-5-Codex: faster, more reliable coding assistant with advanced code reviews
OpenAI unveils GPT-5-Codex, a version of GPT-5 optimized for agentic coding in Codex. It accelerates interactive work, handles long tasks, enhances code reviews, and works across terminal, IDE, web, GitHub, and mobile.